
Google search engine works?
For the website to the TOP SEO requires a lot of technical factors, human, financial … however, understanding the Google search engine is really necessary for any of you want to learn about SEO. We must understand how Google works? Why how Google can return results when you search a certain keyword? And raises the question of the algorithm dilute ngoằng of the Google offering will surely have certain security .. so we can intervene (impact) how to Google “eye” to our website more? How can it “support” for their Top # 1 that are not rivals?
Know how google works can help you more Google-friendly, but that’s not all, you have to set everything to be able to rank high.
1. Parts of Google
Data collection (Spider).
Data analysis – indexed.
Encryption algorithm.

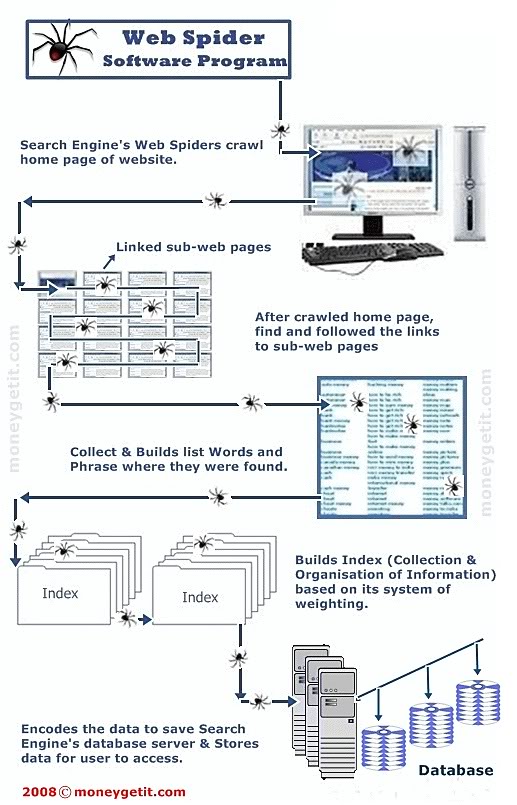
2. Google Spider (search beetles) Crawling & Indexing like?
Spider can:
Crawling through the link on the site has been index Meta designated by name.
Crawling through the Add URL form.
Crawling through Ip server reversed, DNS.
Crawling through the full domain search.
(?)
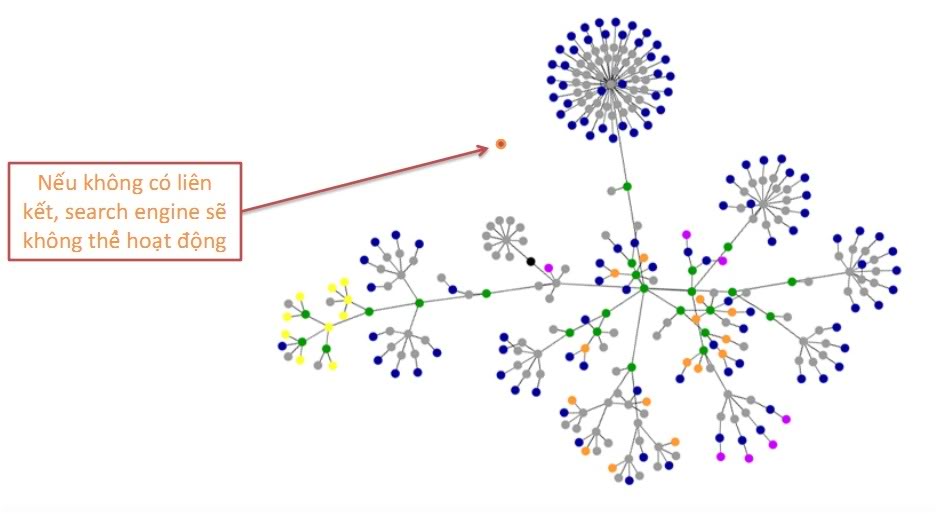
Spider search mechanism
– First Spider retrieve a list of servers and popular sites. Spider will start searching for a site, it’s indexing the words on its pages and following the links (link) found inside this Site. According to this method, the system quick Google search will do the job and spread out all of the most widely used of the web.
– When Spider consider the web pages (HTML format), it noted: from within the site & where it finds the word.
The word appears in the title tag, Meta Description … it said it is an important part related to the user’s search later. So for each website Google it there are many methods to index the index, listing the primary keys. But even way, Google is always trying to make happen faster search system so that users can search more effective, or both.
– Then Google will build the index.
Construction index to allow information to be found quickly. After it finds the information on the website it will recognize that the task of search engine rankings information on the website will not be able to complete … because the webmaster information changes, updated information on the website and that means that Spider always perform tasks Crawling. And make sure that Google will not save the information that it finds a way to benefit the most.
I can take one example as follows: Suppose your website on tourism … it will save the index of your website to the tourist … If your site is about music, it will save the music index your web … and thus avoid finding overlap … because inevitably everyone knows that search engines Google How big data
– It will then encoded information to store the data in its massive database according to an algorithm that … sure it’s very secure.
We can only intervene in the search process of Google in it steps began to search and index the website. What about Google’s algorithm as well as the system it is difficult to be able to interfere. Understanding Google’s search engine will help for SEOER more skills to be able to optimize wwebsite Google-friendly website for the purpose of higher rank.
Check out the video Matt Cutt describe the search process of Google Spidero
Source: vietmoz
Em đang tập seo 1 trang tên là : Chụp ảnh món ăn. Cảm ơn anh, bài viết rất hữu ích